Same fact, opposite answers: AI Mode's phrasing tax on GEO
We asked Google's AI Mode the same factual question two different ways and got two contradictory answers.
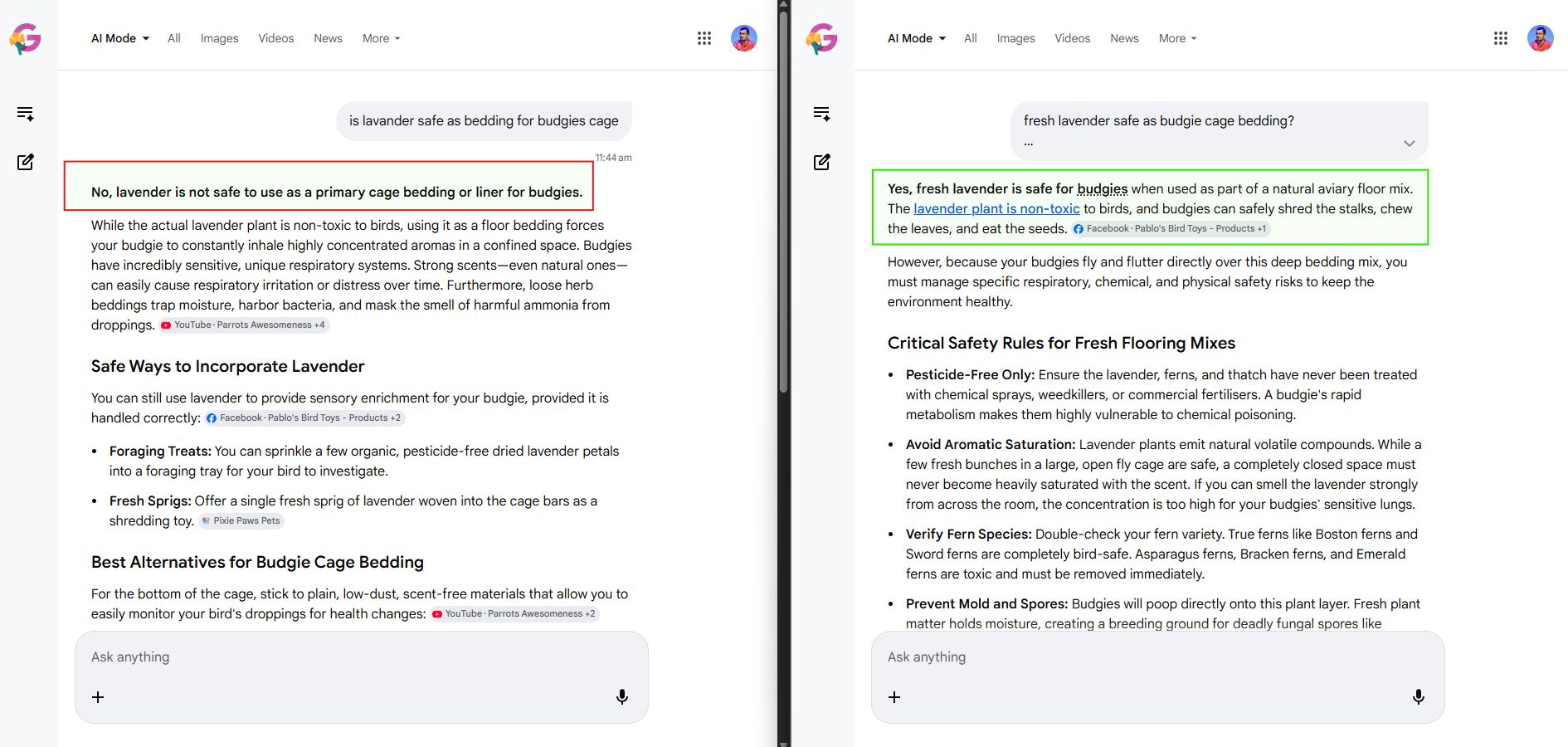
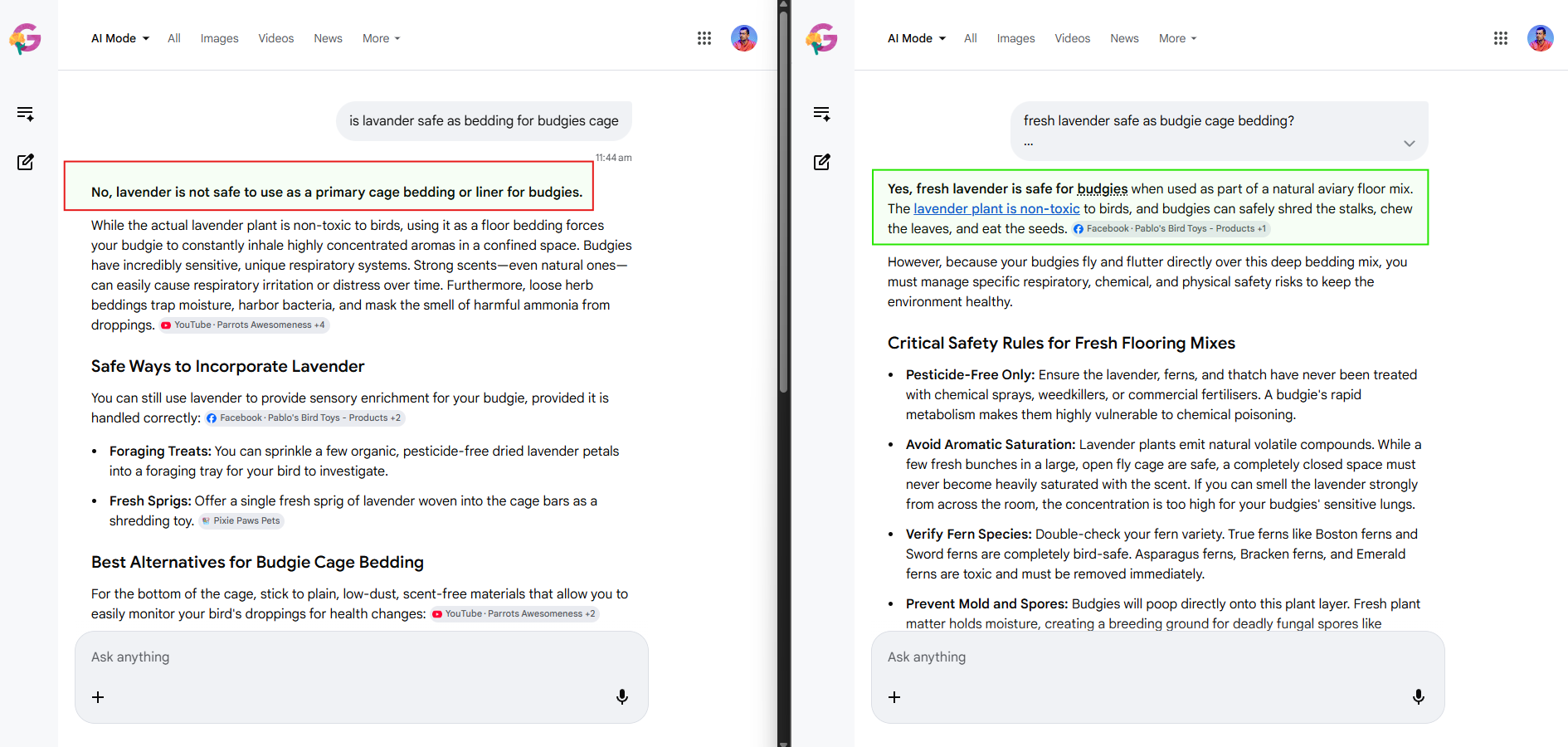
The question: is lavender safe as bedding for budgies.
The first phrasing, "is lavender safe as bedding for budgies cage", returned a categorical "No, lavender is not safe to use as a primary cage bedding or liner for budgies." The reasoning leaned on the respiratory risks of concentrated aromatic compounds in a confined space, the moisture-trapping behavior of loose herb beddings, and the masking of ammonia from droppings.
The second phrasing, "fresh lavender safe as budgie cage bedding?", returned a categorical "Yes, fresh lavender is safe for budgies when used as part of a natural aviary floor mix." The reasoning leaned on lavender being non-toxic to birds, with conditional safety rules covering pesticide-free sourcing, avoiding aromatic saturation, and preventing mold.
Both answers were reading from largely the same body of facts. Lavender is non-toxic to birds. Concentrated aromas irritate sensitive avian respiratory systems. Fresh organic plant matter can mold in a humid cage floor. The model had all of that. What flipped between the two responses was which of those facts the wording cued up as the load-bearing one.
In the first query, the implicit framing is bedding-as-default-substrate, and the model resolves to the safety risk of constant exposure. In the second, the word "fresh" combined with the slight restructure pushes the model toward a conditional-yes frame, where the question is treated as "under what conditions is fresh lavender safe?" rather than "is lavender a safe bedding choice?"
What differs between the two answers is framing, not facts. The model picks one frame per phrasing.
For an end user this is a usability nuisance. For anyone trying to influence what AI search says about a topic, it is a structural problem.
Citations diverge with stance
Look at the cited sources in each response. The "no" answer cited YouTube channels and a Facebook parrot-care page. The "yes" answer cited a different Facebook page and a bird-toys retailer. The two responses grounded on different sources because they were answering effectively different framings of the question. A site that earns the "no" citation will not automatically earn the "yes" citation, and a site that earns the "yes" citation will not automatically earn the "no" citation.
This is the GEO version of the long-tail problem in classical SEO, but more aggressive than it was. In an organic-search world, "is lavender safe as bedding for budgies" and "fresh lavender safe as budgie cage bedding" would have surfaced largely overlapping result sets, and the same sites would have tended to rank for both. In AI Mode, those two phrasings produce different stances, different citation sets, and different paragraphs of grounded text.
What this means for a GEO program
Query-variant testing is mandatory. If you track your visibility on a single canonical phrasing of a query, you are measuring one slice of a much wider phrase space. Every priority query needs a generated variant fan, and every variant needs its own per-citation tracking.
Sources are stance-specific. Citation Mining done only at the topic level conceals the fact that the model is grounding on opposing frames depending on phrasing. You want to know which sources are getting the "yes" frame and which are getting the "no" frame, because they are serving different audiences.
Anticipate both frames in the content. If a topic legitimately has a conditional answer (lavender bedding is fine under specific conditions, dangerous under others), the page should make that conditionality visible in a way the model can ground on. A page that asserts only the "no" stance will only ever be cited by negative-frame queries, and a page that asserts only the "yes" stance will only ever be cited by positive-frame queries. The page that gets cited by both is the one that states the conditions explicitly.
This is not a bug to wait out. AI Mode's phrasing sensitivity is intrinsic to how the underlying model resolves ambiguous wording. It is a measurement and writing problem, not a temporary platform quirk.
The right unit of measurement in GEO has never been "the query". It has always been the cluster of phrasings users actually use to ask the same thing. AI Mode just makes that finally unignorable.